Päivitetty 5.6.2014
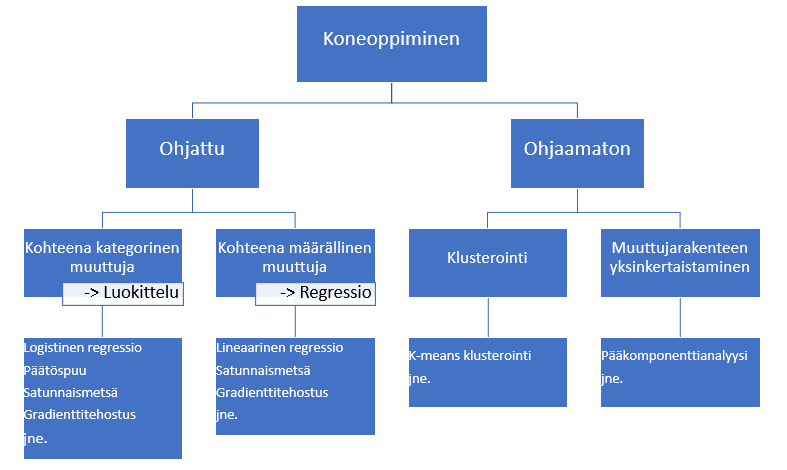
Mistä on kyse?
Esimerkki. Lomaosakkeita myyvä yritys tarjoaa huippuhalvan viikonlopun kylpylässä lomaosakkeen esittelyyn osallistuville. Tarjous kannattaa kohdistaa henkilöille, joiden todennäköisyys lomaosakkeen ostoon on tavanomaista suurempi. Aiempien esittelyiden ja toteutuneiden kauppojen perusteella voidaan laatia malli, jolla lasketaan taustatietojen perusteella henkilön todennäköisyys lomaosakkeen ostoon.
Esimerkki. Luottoriskin arvioimiseksi pankin on hyvä tietää kuinka todennäköisesti luotonottajalle tulee maksuhäiriöitä. Aiempien maksuhäiriöiden perusteella voidaan laatia malli, jolla lasketaan taustatietojen perusteella luotonottajan todennäköisyys maksuhäiriöille.
Esimerkki. Lääkäri diagnosoi sairauden. Aiempien potilaiden potilastietojen perusteella voidaan laatia malli, jolla lasketaan potilaan parantumisen todennäköisyys.
Edellä kuvatuissa esimerkeissä voidaan käyttää todennäköisyyden arviointiin logistista regressiota. Logistista regressiota voidaan käyttää, jos ennustettavana on kategorinen muuttuja: ostaa tai ei osta, tulee maksuhäiriöitä tai ei tule, paranee tai ei parane. Selittävinä muuttujina voi olla sekä määrällisiä että kategorisia muuttujia.
Ilman käsitteiden odds ja logit ymmärtämistä logistista regressiota ei voi ymmärtää, joten aloitan niistä.
Odds
Odds-käsitteelle ei valitettavasti ole vakiintunutta suomennosta. Monet sanakirjat antavat suomennokseksi todennäköisyys, mutta odds on tarkkaan ottaen todennäköisyyksien suhde. Suomennoksia veto, vedonlyöntisuhde ja riski näkyy käytettävän. Minä käytän seuraavassa sekaannuksien välttämiseksi englanninkielistä termiä odds.
Jos tapahtuman todennäköisyys on p, niin odds tapahtuman puolesta:
odds = p / (1-p)
Jos odds on tiedossa, niin yllä olevasta kaavasta voin ratkaista todennäköisyyden:
p = odds / (odds+1)
Esimerkki. Nopanheitossa todennäköisyys saadaa kuutonen on yksi kuudesta (1/6) ja todennäköisyys olla saamatta kuutosta on viisi kuudesta (5/6). Odds on todennäköisyyksien suhde:
- Odds kuutosen puolesta = (1/6)/(5/6)=1/5=0,2
- Odds kuutosta vastaan = (5/6)/(1/6)=5
Logit
Edellisen nopanheittoesimerkin odds 0,2 kuutosen puolesta ja 5 kuutosta vastaan kuvaavat samaa tilannetta eri näkökulmista. Tämä ilmenee jännästi, jos otan logaritmit:
- ln(0,2) ≈ -1,609
- ln(5) ≈ 1,609
Jatketaan nopanheitolla ja tarkastellaan todennäköisyyttä saada parillinen silmäluku. Todennäköisyys on 1/2 ja odds on (1/2)/(1/2)=1. Tässä tapauksessa logaritmi on ln(1)=0.
ln(odds) on niin hyödyllinen, että sille on annettu oma nimi logit:
logit = ln (odds)
Logitilla on muiden muassa seuraavat ominaisuudet:
- Jos todennäköisyys on 50 %, niin logit = 0.
- Jos todennäköisyys on alle 50 %, logit on negatiivinen. Logit on sitä enemmän negatiivinen mitä pienempi todennäköisyys.
- Jos todennäköisyys on yli 50 %, niin logit on positiivinen. Logit on sitä enemmän positiivinen mitä isompi todennäköisyys.
Jatkoa ajatellen on hyvä oppia miten logitista päästään takaisin oddsiin. Tässä tarvitaan luonnollisen logaritmin käänteistoimitusta (e on luonnollisen logaritmin kantaluku eli Neperin luku):
odds=eln(odds)=elogit
Edellä jo totesin, että oddsista saadaa todennäköisyys laskemalla odds/(odds+1). Yhdistämällä tämä tulos äskeiseen, saadaan muunnoskaava logitista todennäköisyyteen:
p = elogit/(1+elogit)
Logistinen regressio
Seuraavassa esimerkkinä käytettävä aineisto SPSS-muodossa logit1.sav (aukeaa vain SPSS:llä) ja Excel-muodossa logit1.xlsx. Kiinnostuksen kohteena on Buy (1=osti, 2=ei ostanut). Seuraavassa on näkyvillä aineiston ensimmäiset rivit:

Selittävinä muuttujina ovat income (tulot), isfemale (1=nainen, 0=mies) ja ismarried (1=naimisissa, 0=naimaton). Otetaan tavoitteeksi laatia malli, jonka avulla voidaan ennustaa oston todennäköisyys muuttujien income, isfemale ja ismarried perusteella.
Logistinen regressiomalli on lineaarinen regressiomalli, jossa selitettävänä muuttujana on logit (todennäköisyyttä ei sellaisenaan saada sovitettua lineaariseen malliin). Esimerkkiaineiston tapauksessa pyrimme muodostamaan mallin
logit = b0+b1*income + b2*isfemale + b3*ismarried
Mallin parametrit (b0, b1, b2, b3) määritetään maximum likelihood eli suurimman uskottavuuden -menetelmällä. Mallin käyttäjän ei välttämättä tarvitse ymmärtää maximum likelihood -menetelmän yksityiskohtia, mutta seuraavat perusideat on hyvä tuntea:
- Parametreille annetaan arvauksena alkuarvot.
- Lasketaan todennäköisyys sille, että havaittu data saataisiin näillä parametrien arvoilla.
- Korjataan parametreja siten että päästään parempaan tulokseen.
- Korjauksia tehdään, kunnes päästään parhaaseen mahdolliseen tulokseen. Paras mahdollinen tulos on se, johon liittyy suurin mahdollinen todennäköisyys sille, että havaittu data saataisiin valituilla parametrien arvoilla.
Esimerkkiaineisto maximum likelihood -menetelmä antaa malliksi:
logit = -12,033 + 0,00016742*income + 1,3653*isfemale + 1,3804*ismarried
Esimerkiksi 50000 ansaitsevan naimattoman naisen logit:
logit = -12,033 + 0,00016742*50000+1,3653*1+1,3804*0 ≈ -2,2967
Edellä jo opimme, että logit voidaan muuntaa todennäköisyydeksi p = elogit/(1+elogit). Näin esimerkiksi 50000 ansaitsevan naimattoman naisen todennäköisyys ostolle:
p = e-2,2967/(1+e-2,2967) ≈ 0,09 = 9 %
SPSS ja logistinen regressio
Voin suorittaa laskennan SPSS:llä seuraavasti:
- Valitsen Analyze – Regression – Binary Logistic.
- Siirrän selitettävän muuttujan Dependent-ruutuun.
- Siirrän selittävät muuttujat Covariates-ruutuun.

SPSS:n tulosteissa on kaksi mallia. Otsikon Block 0 alta löydän tiedot mallista, jossa on ainoastaan vakiotermi b0, mutta ei lainkaan selittäviä muuttujia. Tämä malli on mukana vertailun vuoksi.

Tulosteesta voin lukea, että vakiotermi on -1,478. Tämä tarkoittaa mallia logit=-1,478. Tällöin todennäköisyys p = e-1,478/(1+e-1,478) ≈ 0,1857. Tämä on sama kuin aineistossa niiden osuus, jotka ovat ostaneet (125/673≈0,1857). Pelkästään vakiotermin sisältävä malli siis antaa ostamisen todennäköisyydeksi ostaneiden osuuden. Koska ostaneiden osuus on alle 50 %, niin mallin mukaan ennuste on aina ”ei osta”. Tällainen ennuste osuu kohdalleen 81,4 prosentissa tapauksista (548/673≈0,814).
Varsinaisen selittäviä muuttujia sisältävän mallin tiedot löydän otsikon Block 1 alta. Ensiksi arvioin mallin hyvyyttä verrattuna malliin, jossa on vain vaikiotermi. Hyvyyttä voin arvioida Omnibus-taulukon Model-riviltä. Chi-square-sarake kertoo kuinka paljon -2 Log likelihood (-2 Log likelihoodista lisää artikkelissa Log likelihood) on muuttunut verrattuna pelkästään vakiotermin sisältävään malliin. Tämä muutos noudattaa khiin neliö -jakaumaa, jonka perusteella saadaan muutoksen merkitsevyys (Sig.). Esimerkissämme selittävät muuttujat sisältävä malli on merkitsevästi parempi (Sig.<0,001) kuin pelkästään vakiotermin sisältävä malli.

Model Summary -taulukosta löydän -2 Log likelihood -arvon lisäksi kaksi R2-arvoa (lisätietoa artikkelissa Log likelihood), jotka yrittävät jäljitellä lineaarisen regressiomallin selityskerrointa. Näiden lisäksi on esitetty monia muita tapoja laskea R2-arvo. Yksimielisyyttä parhaasta laskentatavasta ei ole, minkä vuoksi R2-arvojen käyttö ja tulkinta on hankalaa. Aina kuitenkin pätee seuraava: mitä lähempänä R2-arvo on ykköstä sitä parempi.
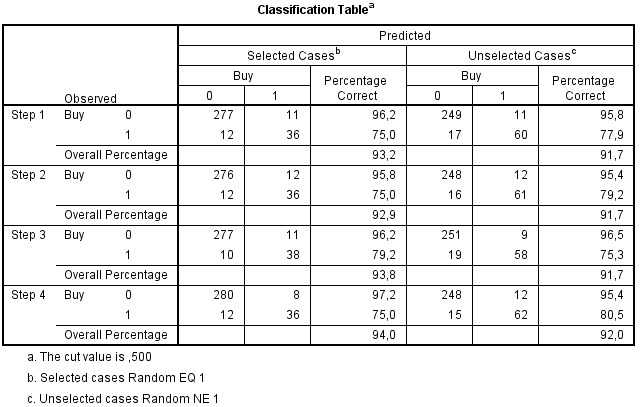
Classification-taulukosta selviää, että malli ennustaa 95,8 % ei ostaneista oikein ja 84,8 % ostaneista oikein. Tässä mielessä malli vaikuttaa onnistuneelta.

Variables in the Equation -taulukko sisältää regressiokertoimet. Income-kerroin (B) ,000 ei tarkoita, että tuloilla ei olisi mitään vaikutusta ostamiseen. Jos lisään desimaalien määrää kyseisessä solussa, niin huomaan kertoimen poikkeavan nollasta.

Varmistan aina, että regressiokertoimet poikkeavat merkitsevästi nollasta. Tämä selviää Wald’in testimuuttujan avulla. Wald’in testimuuttuja saadaan jakamalla kerroin B keskivirheellään S.E. ja korottamalla tulos toiseen potenssiin. Wald’in testimuuttujan tiedetään noudattavan khiin neliö -jakaumaa, jonka perusteella merkitsevyys (Sig.) voidaan laskea. Esimerkissämme kaikki kertoimet poikkeavat merkitsevästi nollasta (Sig.<0,001), joten kaikki selittävät muuttujat voidaan tämän perusteella pitää mallissa mukana.
Malli on siis esimerkkimme tapauksessa (olen ottanut desimaaleja hieman enemmän Variables in the Equation -taulukossa oli näkyvillä):
logit = -12,033 + 0,00016742* income + 1,3653*isfemale + 1,3804*ismarried
Mallin parametrit (kertoimet) voidaan tulkita kuten lineaarisessa mallissa yleensäkin. Esimerkiksi income-kerroin 0,00016742 kertoo, että yhden euron lisäys tuloihin merkitsee 0,00016742 kasvua logitissa. Tämä ei kuitenkaan ole kovinkaan käyttökelpoinen tieto, koska logit on hieman hankala käsite ymmärrettäväksi.
Variables in the Equation -taulukossa on hieman helpommin tulkittavat muunnetut kertoimet Exp(B)-sarakkeessa. Exp(B)-sarakkeen kertoimet kertovat kuinka moninkertaisksi odds muuttuu, kun selittävä muuttuja kasvaa yhdellä yksiköllä.
- Jos tulot kasvat yhdellä eurolla, niin odds kasvaa 1,0001674 kertaiseksi.
- Naisilla odds on 3,917-kertainen miehiin verrattuna.
- Naimisissa olevilla odds on 3,976-kertainen naimattomiin verrattuna.
Selittävien muuttujien valinta
Oma kysymyksensä on selittävien muuttujien valinta, jos ehdolla on paljon mahdollisia selittäviä muuttujia. Tästä lisää artikkelissa Logistinen regressio 2.

































































{kind=link}